After this documentation was released in July 2003, I was approached
by Prentice Hall and asked to write a book on the Linux VM under the Bruce Peren's Open Book Series.
The book is available and called simply "Understanding The Linux Virtual
Memory Manager". There is a lot of additional material in the book that is
not available here, including details on later 2.4 kernels, introductions
to 2.6, a whole new chapter on the shared memory filesystem, coverage of TLB
management, a lot more code commentary, countless other additions and
clarifications and a CD with lots of cool stuff on it. This material (although
now dated and lacking in comparison to the book) will remain available
although I obviously encourge you to buy the book from your favourite book
store :-) . As the book is under the Bruce Perens Open Book Series, it will
be available 90 days after appearing on the book shelves which means it
is not available right now. When it is available, it will be downloadable
from http://www.phptr.com/perens
so check there for more information.
To be fully clear, this webpage is not the actual book.




Next: 3.3 Pages
Up: 3. Describing Physical Memory
Previous: 3.1 Nodes
Contents
Index
Subsections
3.2 Zones
Each zone is described by a struct zone_t. It keeps track of
information like page usage statistics, free area information and locks. It
is declared as follows in  linux/mmzone.h
linux/mmzone.h :
:
37 typedef struct zone_struct {
41 spinlock_t lock;
42 unsigned long free_pages;
43 unsigned long pages_min, pages_low, pages_high;
44 int need_balance;
45
49 free_area_t free_area[MAX_ORDER];
50
76 wait_queue_head_t * wait_table;
77 unsigned long wait_table_size;
78 unsigned long wait_table_shift;
79
83 struct pglist_data *zone_pgdat;
84 struct page *zone_mem_map;
85 unsigned long zone_start_paddr;
86 unsigned long zone_start_mapnr;
87
91 char *name;
92 unsigned long size;
93 } zone_t;
This is a brief explanation of each field in the struct.
- lock Spinlock to protect the zone;
- free_pages Total number of free pages in the zone;
- pages_min, pages_low, pages_high
These are zone watermarks which are described in the
next section;
- need_balance This flag tells the pageout kswapd to
balance the zone;
- free_area Free area bitmaps used by the buddy allocator;
- wait_table A hash table of wait queues of processes waiting on a
page to be freed. This is of importance
to wait_on_page() and
unlock_page(). While processes could all
wait on one queue, this would cause a ``thundering
herd'' of processes to race for pages still locked
when woken up;
- wait_table_size Size of the hash table which is a power of 2;
- wait_table_shift Defined as the number of bits in a long minus
the binary logarithm of the table size above;
- zone_pgdat Points to the parent pg_data_t;
- zone_mem_map The first page in the global mem_map
this zone refers to;
- zone_start_paddr Same principle as node_start_paddr;
- zone_start_mapnr Same principle as node_start_mapnr;
- name The string name of the zone, ``DMA'',
``Normal'' or ``HighMem''
- size The size of the zone in pages.
3.2.1 Zone Watermarks
When available memory in the system is low, the pageout daemon kswapd
is woken up to start freeing pages (see Chapter 11). If the pressure is high, the process will free up memory
synchronously which is sometimes referred to as the direct reclaim
path. The parameters affecting pageout behavior are similar to those used
by FreeBSD [#!mckusick96!#] and Solaris [#!mauro01!#].
Each zone has three watermarks called pages_low,
pages_min and pages_high which help track how much
pressure a zone is under. The number of pages for pages_min
is calculated in the function free_area_init_core() during
memory init and is based on a ratio to the size of the zone in pages. It is
calculated initially as
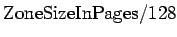 . The lowest value
it will be is 20 pages (80K on a x86) and the highest possible value is 255
pages (1MiB on a x86).
. The lowest value
it will be is 20 pages (80K on a x86) and the highest possible value is 255
pages (1MiB on a x86).
- pages_min When pages_min is reached, the allocator will
do the kswapd work in a synchronous fashion. There
is no real equivalent in Solaris but the closest is the
desfree or minfree which determine
how often the pageout scanner is woken up;
- pages_low When pages_low number of free pages is reached,
kswapd is woken up by the buddy allocator to start
freeing pages. This is equivalent to when lotsfree
is reached in Solaris and freemin in FreeBSD. The
value is twice the value of pages_min by default;
- pages_high Once reached, kswapd is woken, it will not
consider the zone to be ``balanced'' until
pages_high pages are free. In Solaris, this
is called lotsfree and in BSD, it is called
free_target. The default for pages_high
is three times the value of pages_min.
Whatever the pageout parameters are called in each operating system, the
meaning is the same, it helps determine how hard the pageout daemon or
processes work to free up pages.
Next: 3.3 Pages
Up: 3. Describing Physical Memory
Previous: 3.1 Nodes
Contents
Index
Mel
2004-02-15