The mainline or stock kernel is principally distributed as a compressed tape archive (.tar) file available from the nearest kernel source mirror. In Ireland's case, the mirror is located at ftp://ftp.ie.kernel.org. The stock kernel is always the one considered to be released by the tree maintainer. For example, at time of writing, the stock kernels for 2.2.x are those released by Alan Cox, for 2.4.x by Marcelo Tosatti and for 2.5.x by Linus Torvalds. At each release, the full tar file is available as well as a smaller patch which contains the differences between the two releases. Patching is the preferred method of upgrading for bandwidth considerations. Contributions made to the kernel are almost always in the form of patches which is a unified diff generated by the GNU tool diff.
This method of sending patches to be merged to the mailing list initially sounds clumsy but it is remarkable efficient in the kernel development environment. The principal advantage of patches is that it is very easy to show what changes have been made rather than sending the full file and viewing both versions side by side. A developer familiar with the code being patched can easily see what impact the changes will have and if they should be merged. In addition, it is very easy to quote the email from the patch and request more information about particular parts of it. There are scripts available that allow emails to be piped to a script which strips away the mail and keeps the patch available.
BitKeeper allows comments to be associated with each patch which may be displayed as a list as part of the release information for each kernel. For Linux, this means that patches preserve the email that originally submitted the patch or the information pulled from the tree so that the progress of kernel development is a lot more transparent. On release, a summary of the patch titles from each developer is displayed as a list and a detailed patch summary is also available.
As BitKeeper is a proprietary product, which has sparked any number of flame wars2.3 with free software developers, email and patches are still considered the only method for generating discussion on code changes. In fact, some patches will not be considered for acceptance unless there is first some discussion on the main mailing list. In open source software, code quality is considered to be directly related to the amount of peer review. As a number of CVS and plain patch portals are available to the BitKeeper tree and patches are still the preferred means of discussion, it means that at no point is a developer required to have BitKeeper to make contributions to the kernel but the tool is still something that developers should be aware of.
The two tools for creating and applying patches are diff and patch, both of which are GNU utilities available from the GNU website2.4. diff is used to generate patches and patch is used to apply them. While the tools have numerous options, there is a ``preferred usage''.
Patches generated with diff should always be unified diff and generated from one directory above the kernel source root. A unified diff includes more information that just the differences between two lines. It begins with a two line header with the names and creation dates of the two files that diff is comparing. After that, the ``diff'' will consist of one or more ``hunks''. The beginning of each hunk is marked with a line beginning with @@ which includes the starting line in the source code and how many lines there are before and after the hunk is applied. The hunk includes ``context'' lines which show lines above and below the changes to aid a human reader. Each line begins with a +, - or blank. If the mark is +, the line is added. If a -, the line is removed and a blank is to leave the line alone as it is there just to provide context. The reasoning behind generating from one directory above the kernel root is that it is easy to see quickly which version the patch has been applied against and it makes the scripting of applying patches easier if each patch is generated the same way.
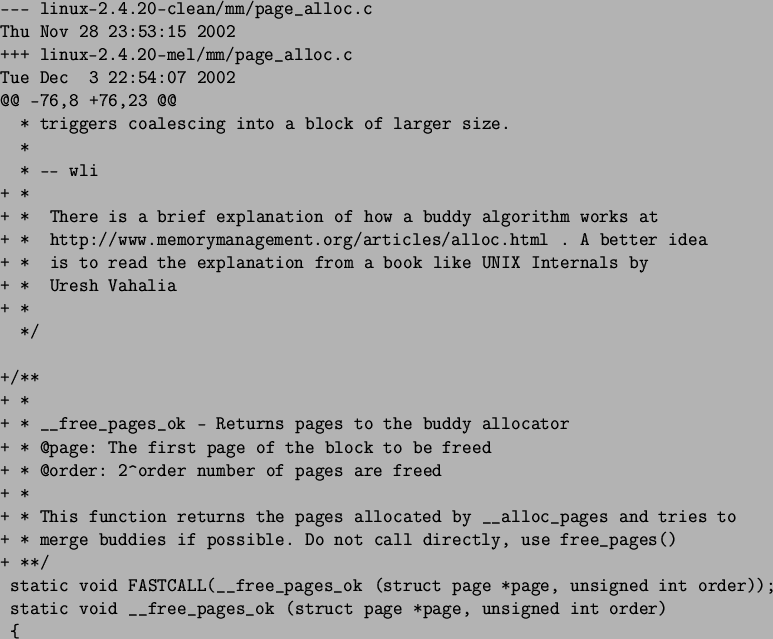
Let us take for example, a very simple change has been made to mm/page_alloc.c which adds a small piece of commentary. The patch is generated as follows. Note that this command should be all on one line minus the backslashes.
mel@joshua: kernels/ $ diff -u \
linux-2.4.20-clean/mm/page_alloc.c \
linux-2.4.20-mel/mm/page_alloc.c > example.patch
This generates a unified context diff (-u switch) between the two files and places the patch in example.patch as shown in Figure 2.1.1.
From this patch, it is clear even at a casual glance which files are affected (page_alloc.c), which line it starts at (76) and that the block was 8 lines before the changes and 23 after them. The new lines are clearly marked with a +. If a patch consists of multiple hunks, each will be treated separately during patch application.
Patches broadly speaking come in two varieties, plain text such as the one above which are sent to the mailing list and a compressed form with gzip (.gz extension) or bzip2 (.bz2 extension). It can be generally assumed that patches are taken from one level above the kernel root and so can be applied with the option -p1. This option means that the patch is generated with the current working directory being one above the Linux source directory and the patch is applied while in the source directory. Broadly speaking, this means a plain text patch to a clean tree can be easily applied as follows:
mel@joshua: kernels/ $ cd linux-2.4.20-clean/ mel@joshua: linux-2.4.20-clean/ $ patch -p1 < ../example.patch patching file mm/page_alloc.c mel@joshua: linux-2.4.20-clean/ $
To apply a compressed patch, it is a simple extension to just decompress the patch to stdout first.
mel@joshua: linux-2.4.20-mel/ $ gzip -dc ../example.patch.gz | patch -p1
If a hunk can be applied but the line numbers are different, the hunk number and the number of lines needed to offset will be output. These are generally safe warnings and may be ignored. If there are slight differences in the context, it will be applied and the level of ``fuzziness'' will be printed which should be double checked. If a hunk fails to apply, it will be saved to filename.c.rej and the original file will be saved to filename.c.orig and have to be applied manually.
When code is small and manageable, it is not particularly difficult to browse through the code as operations are clustered together in the same file and there is not much coupling between modules. The kernel unfortunately does not always exhibit this behavior. Functions of interest may be spread across multiple files or contained as inline functions in headers. To complicate matters, files of interest may be buried beneath architecture specific directories making tracking them down time consuming.
An early solution to the problem of easy code browsing was ctags which could generate tag files from a set of source files. These tags could be used to jump to the C file and line where the function existed with editors such as Vi and Emacs. This method can become cumbersome if there are many functions with the same name. With Linux, this is the case for functions declared in the architecture dependant code.
A more comprehensive solution is available with the Linux Cross-Referencing (LXR) tool available from http://lxr.linux.no. The tool provides the ability to represent source code as browsable web pages. Global identifiers such as global variables, macros and functions become hyperlinks. When clicked, the location where it is defined is displayed along with every file and line referencing the definition. This makes code navigation very convenient and is almost essential when reading the code for the first time.
The tool is very easily installed as the documentation is very clear. For the research of this document, it was deployed at http://monocle.csis.ul.ie which was used to mirror recent development branches. All code extracts shown in this and the companion document were taken from LXR so that the line numbers would be visible.
As separate modules share code across multiple C files, it can be difficult to see what functions are affected by a given code path without tracing through all the code manually. For a large or deep code path, this can be extremely time consuming to answer what should be a simple question.
Based partially on the work of Martin Devera2.5, I developed a tool called gengraph. The tool can be used to generate call graphs from any given C code that has been compiled with a patched version of gcc.
During compilation with the patched compiler, files with a .cdep extension are generated for each C file which list all functions and macros that are contained in other C files as well as any function call that is made. These files are distilled with a program called genfull to generate a full call graph of the entire source code which can be rendered with dot, part of the GraphViz project2.6.
In kernel 2.4.20, there were a total of 28626 entries in the
full.graph file generated by genfull. This call graph
is essentially useless on its own because of its size so a second tool is
provided called gengraph. This program at basic usage takes just
the name of one or more functions as arguments and generates a call graph
with the requested function as the root node. This can result in unnecessary
depth to the graph or graph functions that the user is not interested in,
therefore there are three limiting options to graph generation. The first
is to limit by depth where functions that are greater than ![]() levels deep
in a call chain are ignored. The second is to totally ignore a function so
that neither it nor any of the functions it calls will appear in the call
graph. The last is to display a function, but not traverse it which is
convenient when the function is covered on a separate call graph.
levels deep
in a call chain are ignored. The second is to totally ignore a function so
that neither it nor any of the functions it calls will appear in the call
graph. The last is to display a function, but not traverse it which is
convenient when the function is covered on a separate call graph.
All call graphs shown in these documents are generated
with the gengraph package available at
http://www.csn.ul.ie/![]() mel/projects/gengraph as it is often
much easier to understand a subsystem at first glance when a call graph is
available. It has been tested with a number of other open source projects
based on C and has wider application than just the kernel.
mel/projects/gengraph as it is often
much easier to understand a subsystem at first glance when a call graph is
available. It has been tested with a number of other open source projects
based on C and has wider application than just the kernel.
The untarring of sources, management of patches and building of kernels is initially interesting but quickly palls. To cut down on the tedium of patch management, a tool was developed called patchset designed for the management of kernel sources.
It uses files called set configurations to specify what kernel source tar to use, what patches to apply, what configuration to use for the build and what the resulting kernel is to be called. A sample specification file to build kernel 2.4.20-rmap15a is;
linux-2.4.18.tar.gz 2.4.20-rmap15a config_joshua 1 patch-2.4.19.gz 1 patch-2.4.20.gz 1 2.4.20-rmap15a
This first line says to unpack a source tree starting with linux-2.4.18.tar.gz. The second line specifies that the kernel will be called 2.4.20-rmap15a and the third line specifies which kernel configuration file to use for building the kernel. Each line after that has two parts. The first part says what patch depth to use i.e. what number to use with the -p switch to patch. As discussed earlier in Section 2.1.1, this is usually 1 for applying patches while in the source directory. The second is the name of the patch stored in the patches directory. The above example will apply two patches to update the kernel from 2.4.18 to 2.4.20 before building the 2.4.20-rmap15a kernel tree.
The package comes with three scripts. The first make-kernel.sh will unpack the kernel to the kernels/ directory and build it if requested. If the target distribution is Debian, it can also create Debian packages for easy installation. The second make-gengraph.sh will unpack the kernel but instead of building an installable kernel, it will generate the files required to use gengraph for creating call graphs. The last make-lxr.sh will install the kernel to the LXR root and update the versions so that the new kernel will be displayed on the web page.
With the three scripts, a large amount of the tedium involved with managing
kernel patches is eliminated. The tool is fully documented and freely
available from http://www.csn.ul.ie/![]() mel/projects/patchset.
mel/projects/patchset.